The PDF file format is not supported in WorldServer as a native file format. However, WorldServer provides an Automatic Action (AA) to convert PDF files to DOCX files within a normal workflow.
Note: This action requires that the FTS Server is installed and configured.
Starting from WorldServer 11.7., this AA is renamed to
Convert PDF to DOCX (LIB). In versions before 11.7., the Automatic Action is called
Convert PDF to Word 2007-2010 (LIB). However: Task History entries will still refer to the old name
Convert PDF to Word 2007-2010 (LIB).This Automatic Action converts
PDF file format documents to
Microsoft Word (DOCX) file format. The converted documents can then be translated as
DOCX files. You can add the PDF conversion Automatic Action to a workflow
before the
Segment Asset step where it is executed as part of a project. The AA will detect PDF files and convert them to DOCX files. It will
not convert other file formats so you can place this Automatic Action in any Workflow you are using. If the source file is not a PDF, the step will be skipped. Here is an example of a simple Workflow containing the
Convert PDF to Word 2007-2010 (LIB) Automatic Action:
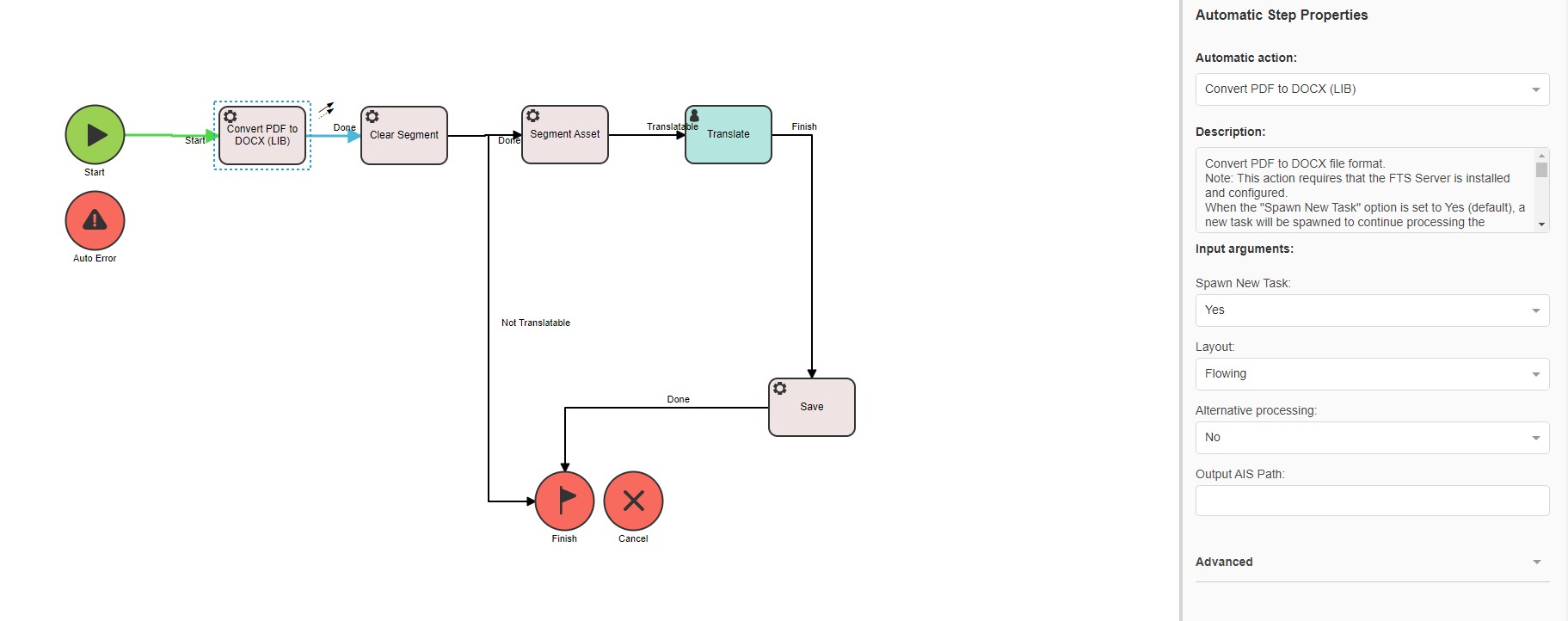
By default, when the conversion from PDF to DOCX completes, the Automatic Action creates a new task that continues executing the workflow using the
DOCX file as an input asset. The original task that performed the PDF conversion is
marked as cancelled.
IMPORTANT: WorldServer does
not convert documents from DOCX back to PDF format. This means that the target file will be in
DOCX format. A conversion back to PDF will need to be done outside of WorldServer and through an external editor as needed.
The conversion happens on the server where the File Type Support (FTS) server service is installed. The conversion tool used in WorldServer versions until 11.8.0 was
Solid Converter. For more information about the conversion tool, visit the
Solid Documents Help Site. However, starting from version 11.8.1 (
FTS 11.8.0.48), the software used to convert PDF files has changed from
Solid to
Sautin and
Aspose. It is the same converter as used in Studio 2022 as PDF File Type. See also:
PDF Assistant for Trados Studio 2022Installation: The
Convert PDF to DOCX (LIB) Automatic Action is distributed in the
autoaction_libraries.zip in the SDK, together with other supported libraries. We assume you have installed this file so please check before following the steps below. If this
Automatic Action is not present in your environment, please upload it following the steps in this article:
How to upload Automatic Actions from the SDK to WorldServer
For WorldServer versions starting from version 11.8.1:
As explained above, starting from version 11.8.x, the software used to convert PDF files has changed from
Solid to
Sautin and
Aspose. Sautin will be used if the setting
Alternative Processing is set to
No (default). If set to
Yes, the software
Aspose will be used. More details about the configuration can be found in this article:
PDF Assistant for Trados Studio 2022When the "
Spawn New Task" option is set to Yes (default), a new task will be spawned to continue processing the converted DOCX file. It should be set to "No" only when this action is standalone within the workflow and no further processing is required.
The "
Output AIS Path" parameter is used to configure the desired output location. When empty (default), the converted docx file will be written to the same location as the source PDF file with only the extension changed from .pdf to .docx. To specify another location, enter a valid AIS folder. (Only file system-based AIS mounts are supported.)
Use the
Layout option to configure the converter behavior:
-
Flowing: recover page layout, columns, graphic and preserve text flow. This is the
default setting.
-
Continuous: detect layout and columns but only recover formatting, graphic and preserve text flow
-
Exact: recover exact page presentation using text boxes in Microsoft Word
The
Alternative Processing option is used to switch to another converter (better for non-latin based languages). The default setting is No. However, when set to yes, the alternative converter will be based on
Aspose as a tool (not
Sautin).
We would like to point out a few limitations and potential solutions:• If you use Asian languages or other non-Latin-based languages as source languages, we recommend that you tick the new checkbox
Use alternative processing (better for non-Latin based languages). • Support for scanned PDF documents using OCR (optical character recognition)
is limited out of the box. If a PDF file contains merely a scanned picture of the underlying document, then the new technology will not be able to convert the document. If, on the other hand, the document is scanned but the text in it is selectable, then the technology will attempt to convert the characters within the document. You can test this in Adobe Reader, for example. If it's possible to select any text in the document, then the technology will attempt to convert it.
• If you need more advanced support for scanned PDF documents, we recommend the following options:
o If you use
Microsoft Word, you can use its built-in PDF conversion - it accepts PDF files, including OCRed, for opening files and can save them out in Word .docx format which you can then process as normal.
o
Adobe Reader also has a built-in function to save PDF documents in Microsoft Word format, which can be purchased as a subscription.
o
Alternatively, consider purchasing a third-party solution, such as Abbyy Fine Reader or Readiris, that can convert OCR'ed PDF documents to Microsoft Word format. These options are available as perpetual licenses or on subscription.
For WorldServer versions before 11.8.x:
You can set several options for the
Convert PDF to Word 2007-2010 (LIB):Image recovery
Default: Automatic AnchoringAnchor the image to the nearest paragraph or the page using the automatically calculated offsets.
Other options:
Anchor to ParagraphAnchor the images to the nearest paragraph
Anchor to Page Anchor the images to the page using the automatically calculated offsets.
Remove Images Remove all images that are not inline.
Headers and footersDefault: Recover as headers and/or footers - Detect headers and footers and add them as Word headers and footers in the output document.
Other options:
Place in the body of the document Handle headers and footers as ordinary text and put them into the body of the output document.
Remove Detect headers and footers but remove them from the output document.
Table detectionDetect TablesDefault =
Yes - Recognize PDF tables and create Word tables from them.
Recognize PDF textYou can control the conversion of symbols when missing or incorrect font encoding is detected during the conversion process to Word. Adjusting these options may help when the text or some symbols in the converted file look garbled.
Note: PDF conversion runs approximately 15 times slower when you enable PDF text recognition, especially if you use the Every character option. This should be avoided.
Default: NoneDo not apply optical text recovery.
Problem characters only Let the application determine where optical text recovery is needed.
Every character Apply optical text recovery to all text. If you need to use this feature, you may also need to reconfigure the
fts_proxy_filter_process_timeout setting in the
general.properties to greater than 30 minutes. WorldServer terminates long-running PDF conversions after the timeout is exceeded.
Other argumentsOutput AIS path Default =
EmptySpecify the desired output location of the converted DOCX file. When empty, the converted .docx file will be written to the same location as the source PDF file with only the extension changed from PDF to DOCX. To specify other locations enter a valid AIS folder.
Note: Only file system-based AIS mounts are supported.
Spawn new taskDefault =
Yes Determine whether a new task should be spawned after the conversion from PDF to DOCX is completed. Set this option to
No when you only require conversion from PDF to DOCX, with no further processing of the resulting DOCX file in the same workflow.
Return values The AA returns
DONE in all cases.
We would like to point out a few limitations and potential solutions:Support for scanned PDF documents using OCR (optical character recognition)
is limited out of the box. If a PDF file contains merely a scanned picture of the underlying document, then the new technology will not be able to convert the document. If, on the other hand, the document is scanned but the text in it is selectable, then the technology will attempt to convert the characters within the document. You can test this in Adobe Reader, for example. If it's possible to select any text in the document, then the technology will attempt to convert it.
• If you need more advanced support for scanned PDF documents, we recommend the following options:
o If you use
Microsoft Word, you can use its built-in PDF conversion - it accepts PDF files, including OCRed, for opening files and can save them out in Word .docx format which you can then process as normal.
o
Adobe Reader also has a built-in function to save PDF documents in Microsoft Word format, which can be purchased as a subscription.
o
Alternatively, consider purchasing a third-party solution, such as Abbyy Fine Reader or Readiris, that can convert OCR'ed PDF documents to Microsoft Word format. These options are available as perpetual licenses or on subscription.

