If you wish to force segmentation after other punctuation marks beside the defaults (full stop, question mark, exclamation mark, etc.) you will need to add new Segmentation Rules to the
Language Processing rule.
To create a
new Segmentation Rule, first, make sure to have Language Processing Rules created.
If there is none, create one from:
Resources > Language Processing Rules > New Language Processing Rule

Next, open the
Language Processing Rule and
Add Entry in the
Customized Language Resources section.
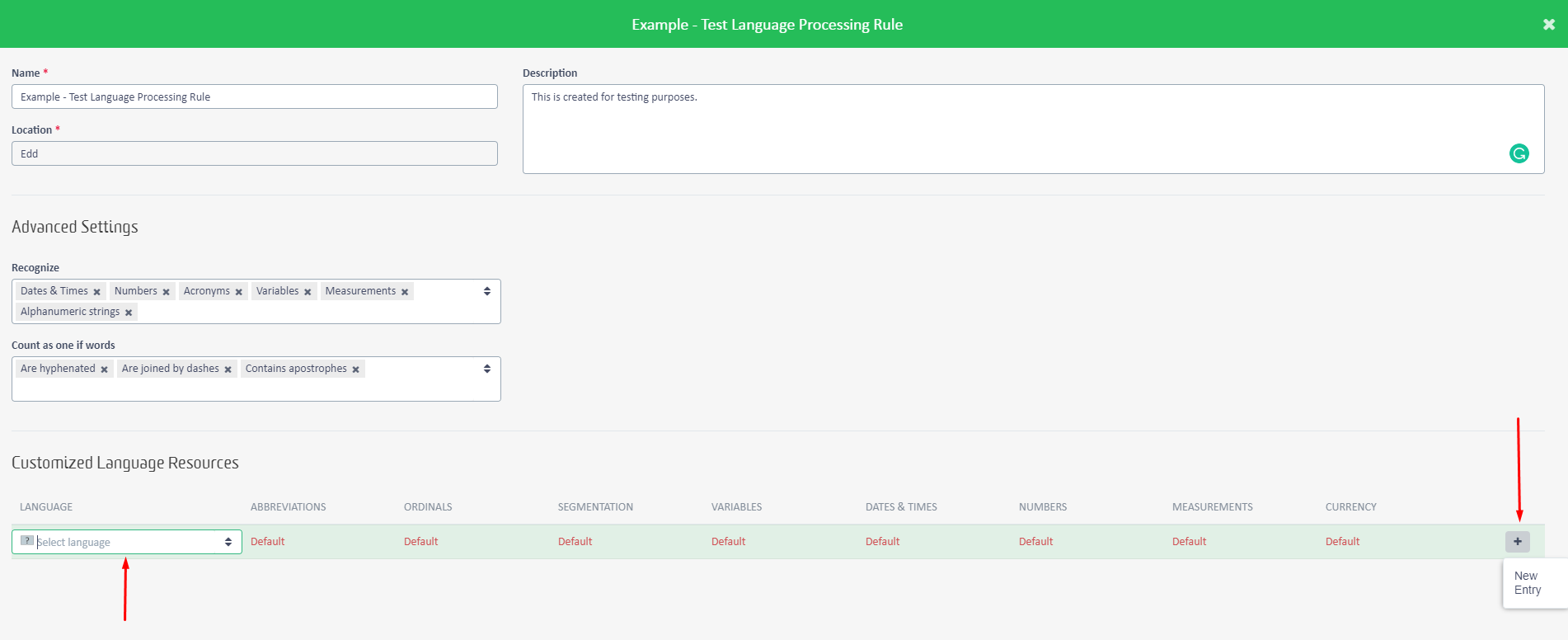
The Language selected must be the Source language.
Note: The new rule will apply ONLY on that source language when using this Language Processing Rule in your Project Template. Any other source languages or project templates are not affected by these settings.
Once you added the Source language, the new Language Processing Rule will open up.
Go to the
Segmentation Rules section and click the
New Entry to add a new rule.
In the
Before Break and
After Break sections, you will need to add your search pattern using
Regular expression.
Example:You have the following text and you wish to segment after the "·" character if before and after this character you have whitespace:
This is a test · Another test · Example ·No Segmentation
Your Before Break and After Break rules should look like this:

Before Break: \s[·]+
After Break: \s
The final segmentation should look like this:
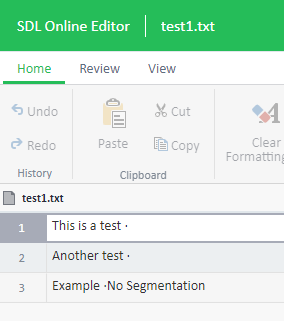
Note: There is no segmentation between Example ·No Segmentation because there is no whitespace after the character.